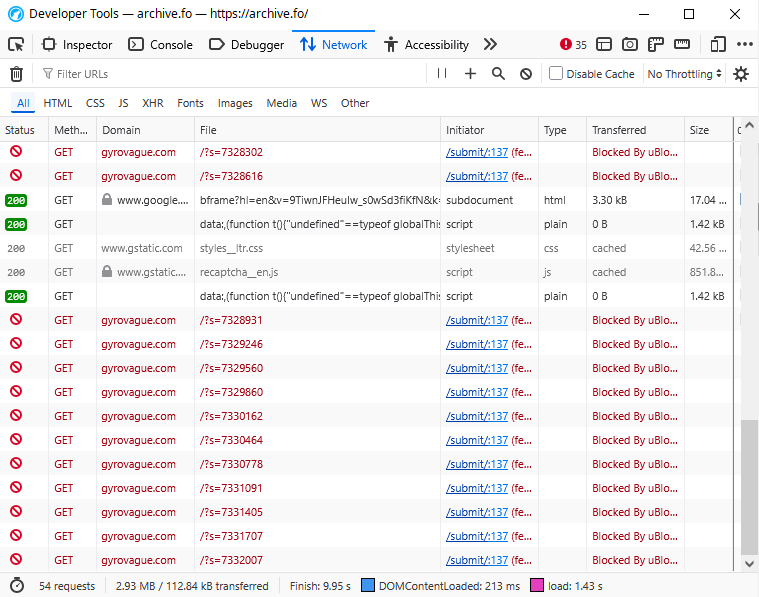
archive.today has recently (I noticed this, like, 3 days ago) started automatically making requests to someone's personal blog on their CAPTCHA page. Here's a screenshot of what I'm talking about: https://files.catbox.moe/20jsle.png
The relevant JS is:
setInterval(function() {
fetch("https://gyrovague.com/?s=" + Math.round(new Date().getTime() % 10000000), {
referrerPolicy: "no-referrer",
mode: "no-cors"
});
}, 300);
So perhaps this is some kind of revenge/DOS attack attempt/deliberately wasting their bandwidth in response to this article? Maybe an attempt to silence them and force to delete their article? But if it is, then I have so many questions. Like, why would the owner of the archive do that 2.5 years after the article was published? Or why would they even do that in the first place, do they not know about Streisand effect?
I'm confused.
Save the page now and compare a week later.
>$ resolvectl query gyrovague.com
gyrovague.com: 192.0.78.25 -- link: eno1
192.0.78.24 -- link: eno1
That said I don't think there's many non-malicious explanation for this, I would suggest writing to HN and see about blocking submissions from the domain hn@ycombinator.com
For example, there was some NASA debris that hit a guy's house in Florida and it was in the news. [1] Some news sites linked to a Twitter post he made with the images but he later deleted the post. [2]
The Wayback Machine has a ton of snapshots of the Twitter post but none of them render for me. [3]
But archive.today's snapshot works great. [4]
[1] https://www.bbc.com/news/articles/c9www02e49zo
[2] https://xcancel.com/Alejandro0tero/status/176872903149342722...
[3] https://web.archive.org/web/20240715000000*/https://twitter....
“Behind the complaints: Our investigation into the suspicious pressure on Archive.today”
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-...
And one where the author's cool with whoever is running archive.today.
One has to wonder why all this tracking from administrator(s) that want to stay anonymous?
You can't trust anything hosted on archive.today because you can't trust that the content hasn't been altered in some way in the pursuit of their agenda.
[0] https://blog.archive.today/post/708008224368001024/why-isnt-... compounded with personal observation.
[1] https://blog.archive.today/post/708565142782246912/pretty-pl...
I’m confused.
> in a 2012 F-Secure forum post, a “masharabinovich” complains about “my website http://archive.is/” being blacklisted. They pop up on Wikipedia as well getting told off for adding too many links to archive.is, including a mention that they’re using the Czech ISP fiber.cz
I can't say for sure whether this is what happened here, but it is a possible explanation.
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-...
In the past week or so, I have received a GDPR takedown attempt of the archive.today blog post (which my hosting provider rightly rejected), a politely worded request to take it down (which was sadly eaten by my spam filter), and now this (thanks to the HN reader who tipped me off).
Given that the proverbial cat has been out of the bag for 2.5 years at this point, I'm genuinely puzzled as to what they're hoping to achieve, but this does not seem like a very good way of going about it.
All that said, the post does not actually dox anyone (as far as I can tell, every name mentioned is an alias or red herring), and the "investigation" was basically punching things into my favorite search engine and seeing what came up. If a nation state level threat actor or even one of the copyright cabals wanted to find the maintainer, they have much better ways of going about it.
I don't think it really matters how "cool" you are with someone while actively trying to doxx them.
https://archive.is/https://gyrovague.com/2023/08/05/archive-...
Do you know when it began?
And what do you think of the account reporting this being named rabinovich, and having being created months ago?
Reports of FBI going hard after archive.today around the time the HN account was setup and they post an archive.today competitor. Pings on the investigative article then a post to HN saying “3 days ago” which could indicate when FBI succeeded.
The only comment by the poster on this article is a sharp clarification of what doxxing is and isn’t.
Perhaps this is just an unusual way of slowly stepping out from behind the curtain on your own quirky terms after a fantastically long tenure.
Funnily enough, they removed that from their talk page right around the time this thread got posted, their first edit in almost 6 years: https://en.wikipedia.org/wiki/Special:Contributions/Masharab...
That's a lot of coincidences...
(For more details on posts getting “rescued”, see Dan’s comment here: >>11662380 )
> All that said, the post does not actually dox anyone (as far as I can tell, every name mentioned is an alias or red herring)
Well, you clearly do have struck a nerve. And the article at least comes off as the attempt to dox someone. Curiosity is one thing, publishing these findings (where the original sources may fade in time) is another. It's quite evident the person behind archive.today does not want the attention. Just saying, your post doesn't exactly say respect privacy. Would you not have published, if you were actually confident to have found the guy? I got the impression, you would have published regardless.
> the "investigation" was basically punching things into my favorite search engine and seeing what came up.
I think that's what doxxing is, for the most part. You did the work, so everyone else doesn't have to. Nation state threat actors and "the copyright cabal" also got other stuff to do, technical feasibility isn't really a valid argument. Nation state actors could also hack, extort, or kill someone. Ethically, that's of no consequence regarding your own actions against someone.
Not saying you are the worst person ever, but I can totally see why you attracted someone's anger.
For the average case, you shouldn't fully trust any one service IMO.
BTW, there is a neat browser add-on, which lets you search across various archives: https://github.com/dessant/web-archives
This is what someone trying to start a treasure hunt like game would say....
Mom! Am I an NPC? Mom! Am I real???
The owner of the site is not identified anywhere on the site itself. And I think we can both agree that it's the sort of site whose owner would prefer to remain as anonymous as possible. The blog post digs up information about the owner from whois records, which do count as easily accessible public information, but then links to Kiwifarms of all places, and goes on to talk about identifying writing patterns and doing "detective work" involving cross-referencing profile pictures of accounts on various websites that were obviously not intentionally linked together by their owner. This is a textbook doxxing attempt.
{
echo resolve web.archive.org:443:207.241.237.3
echo url=https://web.archive.org/web/20240404223104if_/https://twitter.com/Alejandro0tero/status/1768729031493427225
echo user-agent=\"\"
echo header accept:
} \
|curl -qK/dev/stdin|tr \< '\n'|sed -n '/^meta/s/^/</;/./{/og:url/,/og:image/p;}'The author of the personal blog post claimed he works for Google, who has arguably the world's most complete web archive and uses it for commercial purposes
This archive used to be publicly accessible, at least in part, at webcache.googleusercontent.com^1
The blog post compares the size of archive.today with archive.org (about 1:40, according to the author)
But it does not include a comparison to cache.googleusercontent.com
1. Bing, another Google competitor, also offered part of their own archive at cc.bingj.com during that time
I've had email correspondence with gyrovague where they've shared this exact sentiment.
RT content verboten in Germany, DW content verboten in Russia, not to mention another dozen of hot spots.
"Other websites" are completely inaccessible in certain regions. The Archive has stuff from all of them, so there’s basically no place on Earth where it could work without tricks like the EDNS one.
You're saying they have groups of servers with every possible permutation of censorship that they direct clients to through DNS? Absurd.
Isn't that true of archive.org as well? Why doesn't it need EDNS then?
It's a rather interesting question for archive.org, if one were to interview them, that is.
Unlike archive.today, they don't appear to have any issues with e.g. child pornography content, despite certainly hosting a hundred times more material.
They have some strong magic which makes the cheap tricks needless.
{kind=link}