https://www.alignmentforum.org/posts/6Xgy6CAf2jqHhynHL/what-...
//edit: remove the referral tags from URL
This is an article that describes a pretty good approach for that: https://getstream.io/blog/cursor-ai-large-projects/
But do skip (or at least significantly postpone) enabling the 'yolo mode' (sigh).
For 3D models, check out blender-mcp:
https://old.reddit.com/r/singularity/comments/1joaowb/claude...
https://old.reddit.com/r/aiwars/comments/1jbsn86/claude_crea...
Also this:
https://old.reddit.com/r/StableDiffusion/comments/1hejglg/tr...
For teaching, I'm using it to learn about tech I'm unfamiliar with every day, it's one of the things it's the most amazing at.
For the things where the tolerance for mistakes is extremely low and the things where human oversight is extremely importamt, you might be right. It won't have to be perfect (just better than an average human) for that to happen, but I'm not sure if it will.
> I wonder who pays the bills of the authors. And your bills, for that matter.
Also, what a weirdly conspiratorial question. There's a prominent "Who are we?" button near the top of the page and it's not a secret what any of the authors did or do for a living.
This forum has been so behind for too long.
Sama has been saying this a decade now: “Development of Superhuman machine intelligence is probably the greatest threat to the continued existence of humanity” 2015 https://blog.samaltman.com/machine-intelligence-part-1
Hinton, Ilya, Dario Amodei, RLHF inventor, Deepmind founders. They all get it, which is why they’re the smart cookies in those positions.
First stage is denial, I get it, not easy to swallow the gravity of what’s coming.
Manifold currently predicts 30%: https://manifold.markets/IsaacKing/ai-2027-reports-predictio...
A lot of this resembles post-war futurism that assumed we would all be flying around in spaceships and personal flying cars within a decade. Unfortunately the rapid pace of transportation innovation slowed due to physical and cost constraints and we've made little progress (beyond cost optimization) since.
This is the real scary bit. I'm not convinced that AI will ever be good enough to think independently and create novel things without some serious human supervision, but none of that matters when applied to machines that are destructive by design and already have expectations of collateral damage. Slaughterbots are going to be the new WMDs — and corporations are salivating at the prospect of being first movers. https://www.youtube.com/watch?v=UiiqiaUBAL8
It was surpassed around the beginning of this year, so you'll need to come up with a new one for 2027. Note that the other opinions in that older HN thread almost all expected less.
I suspect something similar will come for the people who actually believe this.
https://apnews.com/article/artificial-intelligence-fighter-j...
Plug: We built https://RadPod.ai to allow you to do that, i.e. Deep Research on your data.
https://www.lesswrong.com/posts/u9Kr97di29CkMvjaj/evaluating...
The pattern where Scott Alexander puts forth a huge claim and then immediately hedges it backward is becoming a tiresome theme. The linguistic equivalent of putting claims into a superposition where the author is both owning it and distancing themselves from it at the same time, leaving the writing just ambiguous enough that anyone reading it 5 years from now couldn't pin down any claim as false because it was hedged in both directions. Schrödinger's prediction.
> Do we really think things will move this fast? Sort of no
> So maybe think of this as a vision of what an 80th percentile fast scenario looks like - not our precise median, but also not something we feel safe ruling out.
The talk of "not our precise median" and "Not something we feel safe ruling out" is an elaborate way of hedging that this isn't their actual prediction but, hey, anything can happen so here's a wild story! When the claims don't come true they can just point back to those hedges and say that it wasn't really their median prediction (which is conveniently not noted).
My prediction: The vague claims about AI becoming more powerful and useful will come true because, well, they're vague. Technology isn't about to reverse course and get worse.
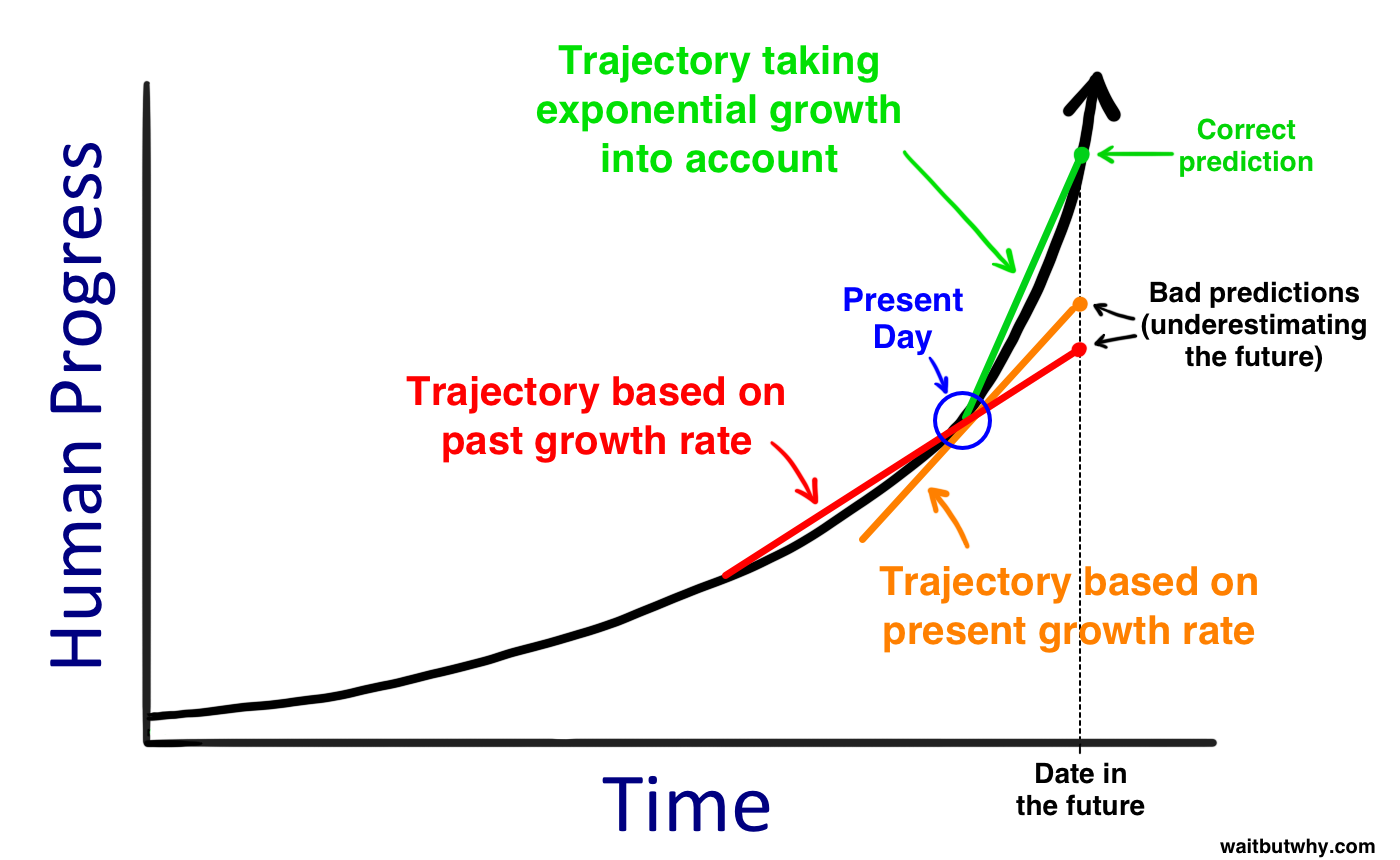
The actual bold claims like humanity colonizing space in the late 2020s with the help of AI are where you start to realize how fanciful their actual predictions are. It's like they put a couple points of recent AI progress on a curve, assumed an exponential trajectory would continue forever, and extrapolated from that regression until AI was helping us colonize space in less than 5 years.
> Manifold currently predicts 30%:
Read the fine print. It only requires 30% of judges to vote YES for it to resolve to YES.
This is one of those bets where it's more about gaming the market than being right.
I assume that thanks to the universal approximation theorem it’s theoretically possible to emulate the physical mechanism, but at what hardware and training cost? I’ve done back of the napkin math on this before [1] and the number of “parameters” in the brain is at least 2-4 orders of magnitude more than state of the art models. But that’s just the current weights, what about the history that actually enables the plasticity? Channel threshold potentials are also continuous rather than discreet and emulating them might require the full fp64 so I’m not sure how we’re even going to get to the memory requirements in the next decade, let alone whether any architecture on the horizon can emulate neuroplasticity.
Then there’s the whole problem of a true physical feedback loop with which the AI can run experiments to learn against external reward functions and the core survival reward function at the core of evolution might itself be critical but that’s getting deep into the research and philosophy on the nature of intelligence.
[1] >>40313672
https://www.theguardian.com/technology/2017/apr/18/god-in-th...
In section 4 they discuss their projections specifically for model size, the state of inference chips in 2027, etc. It's largely pretty in line with expectations in terms of the capacity, and they only project them using 10k of their latest gen wafer scale inference chips by late 2027, roughly like 1M H100 equivalents. That doesn't seem at all impossible. They also earlier on discuss expectations for growth in efficiency of chips, and for growth in spending, which is only ~10x over the next 2.5 years, not unreasonable in absolute terms at all given the many tens of billions of dollars flooding in.
So on the "can we train the AI" front, they mostly are just projecting 2.5 years of the growth in scale we've been seeing.
The reason they predict a fairly hard takeoff is they expect that distillation, some algorithmic improvements, and iterated creation of synthetic data, training, and then making more synthetic data will enable significant improvements in efficiency of the underlying models (something still largely in line with developments over the last 2 years). In particular they expect a 10T parameter model in early 2027 to be basically human equivalent, and they expect it to "think" at about the rate humans do, 10 words/second. That would require ~300 teraflops of compute per second to think at that rate, or ~0.1H100e. That means one of their inference chips could potentially run ~1000 copies (or fewer copies faster etc. etc.) and thus they have the capacity for millions of human equivalent researchers (or 100k 40x speed researchers) in early 2027.
They further expect distillation of such models etc. to squeeze the necessary size down / more expensive models overseeing much smaller but still good models squeezing the effective amount of compute necessary, down to just 2T parameters and ~60 teraflops each, or 5000 human-equivalents per inference chip, making for up to 50M human-equivalents by late 2027.
This is probably the biggest open question and the place where the most criticism seems to me to be warranted. Their hardware timelines are pretty reasonable, but one could easily expect needing 10-100x more compute or even perhaps 1000x than they describe to achieve Nobel-winner AGI or superintelligence.
You may find this to be insightful: https://meltingasphalt.com/a-nihilists-guide-to-meaning/
In short, "meaning" is a contextual perception, not a discrete quality, though the author suggests it can be quantified based on the number of contextual connections to other things with meaning. The more densely connected something is, the more meaningful it is; my wedding is meaningful to me because my family and my partners family are all celebrating it with me, but it was an entirely meaningless event to you.
Thus, the meaningfulness of our contributions remains unchanged, as the meaning behind them is not dependent upon the perspective of an external observer.
Science is not ideas: new conceptual schemes must be invented, confounding variables must be controlled, dead-ends explored. This process takes years.
Engineering is not science: kinks must be worked out, confounding variables incorporated. This process also takes years.
Technology is not engineering: the purely technical implementation must spread, become widespread and beat social inertia and its competition, network effects must be established. Investors and consumers must be convinced in the long term. It must survive social and political repercussions. This process takes yet more years.
I think thats just not true: https://en.wikipedia.org/wiki/Peasants%27_Revolt
A large number of revolutions/rebellions are caused by mass unemployment or famine.
You may consider using search to be cheating, but we do it, so why shouldn't LLMs?
Can you point to the data that suggests these evil corporations are ruining the planet? Carbon emissions are down in every western country since 1990s. Not down per-capita, but down in absolute terms. And this holds even when adjusting for trade (i.e. we're not shipping our dirty work to foreign countries and trading with them). And this isn't because of some regulation or benevolence. It's a market system that says you should try to produce things at the lowest cost and carbon usage is usually associated with a cost. Get rid of costs, get rid of carbon.
Other measures for Western countries suggests the water is safer and overall environmental deaths have decreased considerably.
The rise in carbon emissions is due to Chine and India. Are you talking about evil Chinese and Indians corporations?
The problem with this argument is that it's assuming that we're on a linear track to more and more intelligent machines. What we have with LLMs isn't this kind of general intelligence.
We have multi-paragraph autocomplete that's matching existing texts more and more closely. The resulting models are great priors for any kind of language processing and have simple reasoning capabilities in so far as those are present in the source texts. Using RLHF to make the resulting models useful for specific tasks is a real achievement, but doesn't change how the training works or what the original training objective was.
So let's say we continue along this trajectory and we finally have a model that can faithfully reproduce and identify every word sequence in its training data and its training data includes every word ever written up to that point. Where do we go from here?
Do you want to argue that it's possible that there is a clever way to create AGI that has nothing to do with the way current models work and that we should be wary of this possibility? That's a much weaker argument than the one in the article. The article extrapolates from current capabilities - while ignoring where those capabilities come from.
> And, even if you think A or B are unlikely, doesn't it make sense to just consider the possibility that they're true, and think about how we'd know and what we could do in response, to prevent C or D?
This is essentially https://plato.stanford.edu/entries/pascal-wager/
It might make sense to consider, but it doesn't make sense to invest non-trivial resources.
This isn't the part that bothers me at all. I know people who got grants from, e.g., Miri to work on research in logic. If anything, this is a great way to fund some academic research that isn't getting much attention otherwise.
The real issue is that people are raising ridiculous amounts of money by claiming that the current advances in AI will lead to some science fiction future. When this future does not materialize it will negatively affect funding for all work in the field.
And that's a problem, because there is great work going on right now and not all of it is going to be immediately useful.
This just isn't correct. Daniel and others on the team are experienced world class forecasters. Daniel wrote another version of this in 2021 predicting the AI world in 2026 and was astonishingly accurate. This deserves credence.
https://www.lesswrong.com/posts/6Xgy6CAf2jqHhynHL/what-2026-...
>he arguments back then went something like this: "Machines will be able to simulate brains at higher and higher fidelity.
Complete misunderstanding of the underlying ideas. Just in not even wrong territory.
>We got some new, genuinely useful tools over the last few years, but this narrative that AGI is just around the corner needs to die. It is science fiction and leads people to make bad decisions based on fictional evidence.
You are likely dangerously wrong. The AI field is near universal in predicting AGI timelines under 50 years. With many under 10. This is an extremely difficult problem to deal with and ignoring it because you think it's equivalent to overpopulation on mars is incredibly foolish.
https://www.metaculus.com/questions/5121/date-of-artificial-...
https://wiki.aiimpacts.org/doku.php?id=ai_timelines:predicti...
https://x.com/RnaudBertrand/status/1901133641746706581
I finally watched Ne Zha 2 last night with my daughters.
It absolutely lives up to the hype: undoubtedly the best animated movie I've ever seen (and I see a lot, the fate of being the father of 2 young daughters ).
But what I found most fascinating was the subtle yet unmistakable geopolitical symbolism in the movie.
Warning if you haven't yet watched the movie: spoilers!
So the story is about Ne Zha and Ao Bing, whose physical bodies were destroyed by heavenly lightning. To restore both their forms, they must journey to the Chan sect—headed by Immortal Wuliang—and pass three trials to earn an elixir that can regenerate their bodies.
The Chan sect is portrayed in an interesting way: a beacon of virtue that all strive to join. The imagery unmistakably refers to the US: their headquarters is an imposingly large white structure (and Ne Zha, while visiting it, hammers the point: "how white, how white, how white") that bears a striking resemblance to the Pentagon in its layout. Upon gaining membership to the Chan sect, you receive a jade green card emblazoned with an eagle that bears an uncanny resemblance to the US bald eagle symbol. And perhaps most telling is their prized weapon, a massive cauldron marked with the dollar sign...
Throughout the movie you gradually realize, in a very subtle way, that this paragon of virtue is, in fact, the true villain of the story. The Chan sect orchestrates a devastating attack on Chentang Pass—Ne Zha's hometown—while cunningly framing the Dragon King of the East Sea for the destruction. This manipulation serves their divide-and-conquer strategy, allowing them to position themselves as saviors while furthering their own power.
One of the most pointed moments comes when the Dragon King of the East Sea observes that the Chan sect "claims to be a lighthouse of the world but harms all living beings."
Beyond these explicit symbols, I was struck by how the film portrays the relationships between different groups. The dragons, demons, and humans initially view each other with suspicion, manipulated by the Chan sect's narrative. It's only when they recognize their common oppressor that they unite in resistance and ultimately win. The Chan sect's strategy of fostering division while presenting itself as the arbiter of morality is perhaps the key message of the movie: how power can be maintained through control of the narrative.
And as the story unfolds, Wuliang's true ambition becomes clear: complete hegemony. The Chan sect doesn't merely seek to rule—it aims to establish a system where all others exist only to serve its interests, where the dragons and demons are either subjugated or transformed into immortality pills in their massive cauldron. These pills are then strategically distributed to the Chan sect's closest allies (likely a pointed reference to the G7).
What makes Ne Zha 2 absolutely exceptional though is that these geopolitical allegories never overshadow the emotional core of the story, nor its other dimensions (for instance it's at times genuinely hilariously funny). This is a rare film that makes zero compromise, it's both a captivating and hilarious adventure for children and a nuanced geopolitical allegory for adults.
And the fact that a Chinese film with such unmistakable anti-American symbolism has become the highest-grossing animated film of all time globally is itself a significant geopolitical milestone. Ne Zha 2 isn't just breaking box office records—it's potentially rewriting the rules about what messages can dominate global entertainment.
Daniel Dennett - Information & Artificial Intelligence
https://www.youtube.com/watch?v=arEvPIhOLyQ
Daniel Dennett bridges the gap between everyday information and Shannon-Weaver information theory by rejecting propositions as idealized meaning units. This fixation on propositions has trapped philosophers in unresolved debates for decades. Instead, Dennett proposes starting with simple biological cases—bacteria responding to gradients—and recognizing that meaning emerges from differences that affect well-being. Human linguistic meaning, while powerful, is merely a specialized case. Neural states can have elaborate meanings without being expressible in sentences. This connects to AI evolution: "good old-fashioned AI" relied on propositional logic but hit limitations, while newer approaches like deep learning extract patterns without explicit meaning representation. Information exists as "differences that make a difference"—physical variations that create correlations and further differences. This framework unifies information from biological responses to human consciousness without requiring translation into canonical propositions.
IMO this out of distribution learning is all we need to scale to AGI. Sure there are still issues, it doesn't always know which distribution to pick from. Neither do we, hence car crashes.
[1]: https://arxiv.org/pdf/2303.12712 or on YT https://www.youtube.com/watch?v=qbIk7-JPB2c
As others have pointed out in other threads RLHF has progressed beyond next-token prediction and modern models are modeling concepts [1].
[0] https://metr.org/blog/2025-03-19-measuring-ai-ability-to-com...
[1] https://www.anthropic.com/news/tracing-thoughts-language-mod...
And when there were the first murmurings that maybe we're finally hitting a wall the labs published ways to harness inference-time compute to get better results which can be fed back into more training.
Anthropic recently released research where they saw how when Claude attempted to compose poetry, it didn't simply predict token by token and "react" to when it thought it might need a rhyme and then looked at its context to think of something appropriate, but actually saw several tokens ahead and adjusted for where it'd likely end up, ahead of time.
Anthropic also says this adds to evidence seen elsewhere that language models seem to sometimes "plan ahead".
Please check out the section "Planning in poems" here; it's pretty interesting!
https://transformer-circuits.pub/2025/attribution-graphs/bio...
No one is stigmatizing anything. Just that if you consume doom porn it's likely to affect your attitudes towards life. I think it's a lot healthier to believe you can change your circumstances than to believe you are doomed because you believe you have the wrong brain
https://www.nature.com/articles/s41380-022-01661-0
https://www.quantamagazine.org/the-cause-of-depression-is-pr...
https://www.ucl.ac.uk/news/2022/jul/analysis-depression-prob...
OK, I think I see where you're coming from. It sounds like what you're saying is:
E. LLMs only do multi-paragraph autocomplete; they are and always will be incapable of actual thinking.
F. Any approach capable of achieving AGI will be completely different in structure. Who knows if or when this alternate approach will even be developed; and if it is developed, we'll be starting from scratch, so we'll have plenty of time to worry about progress then.
With E, again, it may or may not be true. It's worth noting that this is a theoretical argument, not an empirical one; but I think it's a reasonable assumption to start with.
However, there are actually theoretical reasons to think that E may be false. The best way to predict the weather is to have an internal model which approximates weather systems; the best way to predict the outcome of a physics problem is to have an internal model which approximates the physics of the thing you're trying to predict. And the best way to predict what a human would write next is to have a model of a human mind -- including a model of what the human mind has in its model (e.g., the state of the world).
There is some empirical data to support this argument, albeit in a very simplified manner: They trained a simple LLM to predict valid moves for Othello, and then probed it and discovered an internal Othello board being simulated inside the neural network:
https://thegradient.pub/othello/
And my own experience with LLMs better match the "LLMs have an internal model of the world" theory than the "LLMs are simply spewing out statistical garbage" theory.
So, with regard to E: Again, sure, LLMs may turn out to be a dead end. But I'd personally give the idea that LLMs are a complete dead end a less than 50% probability; and I don't think giving it an overwhelmingly high probability (like 1 in a million of being false) is really reasonable, given the theoretical arguments and empirical evidence against it.
With regard to F, again, I don't think this is true. We've learned so much about optimizing and distilling neural nets, optimizing training, and so on -- not to mention all the compute power we've built up. Even if LLMs are a dead end, whenever we do find an architecture capable of achieving AGI, I think a huge amount of the work we've put into optimizing LLMs will put is way ahead in optimizing this other system.
> ...that the current advances in AI will lead to some science fiction future.
I mean, if you'd told me 5 years ago that I'd be able to ask a computer, "Please use this Golang API framework package to implement CRUD operations for this particular resource my system has", and that the resulting code would 1) compile out of the box, 2) exhibit an understanding of that resource and how it relates to other resources in the system based on having seen the code implementing those resources 3) make educated guesses (sometimes right, sometimes wrong, but always reasonable) about details I hadn't specified, I don't think I would have believed you.
Even if LLM progress is logarithmic, we're already living in a science fiction future.
EDIT: The scenario actually has very good technical "asides"; if you want to see their view of how a (potentially dangerous) personality emerges from "multi-paragraph auto-complete", look at the drop-down labelled "Alignment over time", and specifically what follows "Here’s a detailed description of how alignment progresses over time in our scenario:".
> estimates that the globally available AI-relevant compute will grow by a factor of 10x by December 2027 (2.25x per year) relative to March 2025 to 100M H100e.
Meanwhile, back in the real March 2025, Microsoft and Google slash datacenter investment.
https://theconversation.com/microsoft-cuts-data-centre-plans...
The summary at https://ai-2027.com outlines a predictive scenario for the impact of superhuman AI by 2027. It involves two possible endings: a "slowdown" and a "race." The scenario is informed by trend extrapolations, expert feedback, and previous forecasting successes. Key points include:
- *Mid-2025*: AI agents begin to transform industries, though they are unreliable and expensive. - *Late 2025*: Companies like OpenBrain invest heavily in AI research, focusing on models that can accelerate AI development. - *Early 2026*: AI significantly speeds up AI research, leading to faster algorithmic progress. - *Mid-2026*: China intensifies its AI efforts through nationalization and resource centralization, aiming to catch up with Western advancements.
The scenario aims to spark conversation about AI's future and how to steer it positively[1].
Sources [1] ai-2027.com https://ai-2027.com [2] AI 2027 https://ai-2027.com
https://old.reddit.com/r/singularity/comments/1jl5qfs/its_ju...
FWIW, this guy thinks E is true, and that he has a better direction to head in:
https://www.youtube.com/watch?v=ETZfkkv6V7Y
HN discussion about a related article I didn't read:
I agree with you on construction and physical work.
"Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war." https://www.safe.ai/work/statement-on-ai-risk
Laughing it off as the same as the Second Coming CANNOT work. Unless you think yourself cleverer and more capable of estimating the risk than all of these experts in the field.
Especially since many of them have incentives that should prevent them from penning such a letter.
But let's take for granted that we are putting exponential scaling to good use in terms of compute resources. It looks like we are seeing sublinear performance improvements on actual benchmarks[1]. Either way it seems optimistic at best to conclude that 1000x more compute would yield even 10x better results in most domains.
[1]fig.1 AI performance relative to human baseline. (https://hai.stanford.edu/ai-index/2025-ai-index-report)
{kind=link}