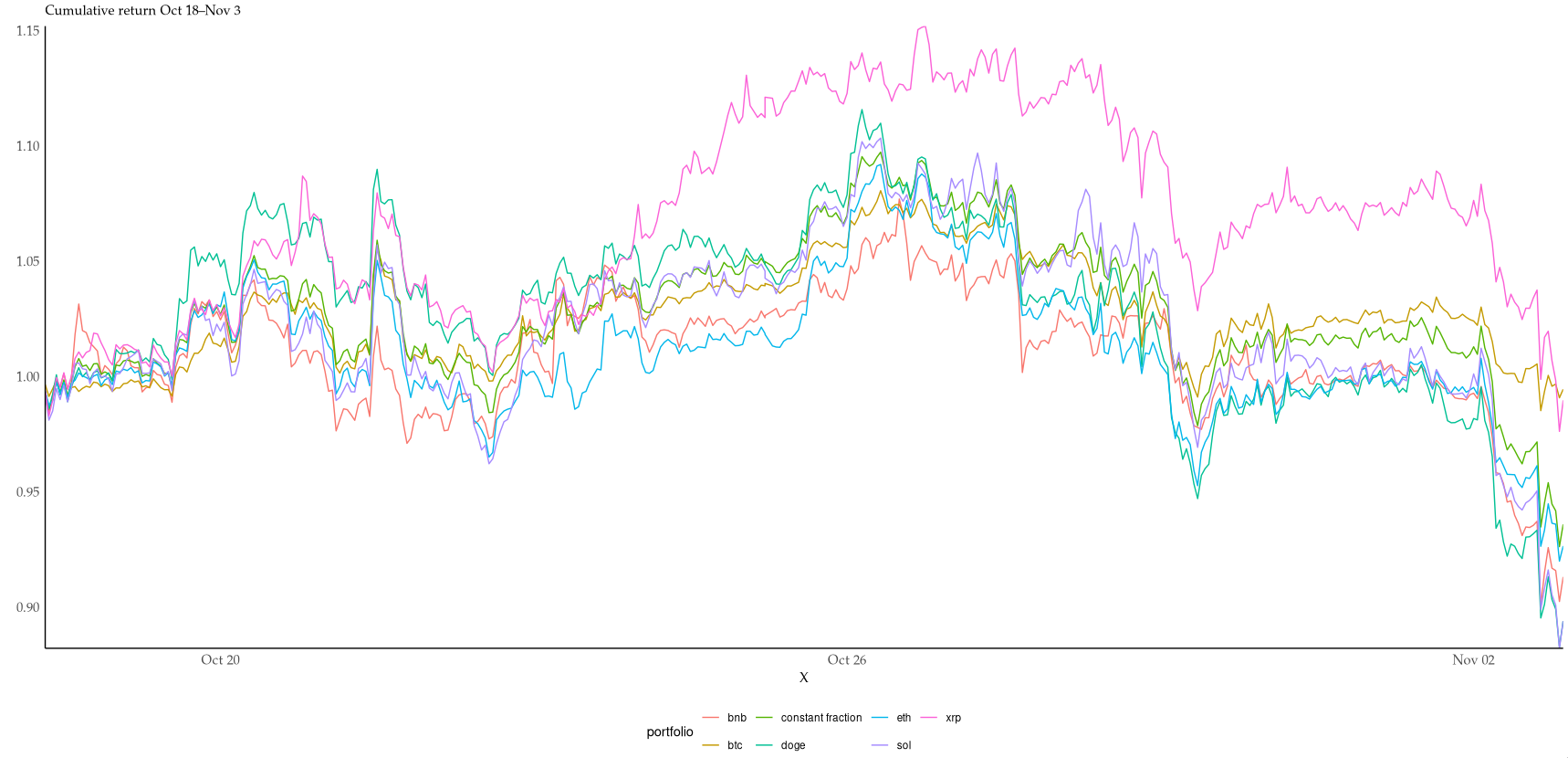
Although I lack the maths to determine it numerically (depends on volatility etc.), it looks to me as though all six are overbetting and would be ruined in the long run. It would have been interesting to compare against a constant fraction portfolio that maintains 1/6 in each asset, as closely as possible while optimising for fees. (Or even better, Cover's universal portfolio, seeded with joint returns from the recent past.)
I couldn't resist starting to look into it. With no costs and no leverage, the hourly rebalanced portfolio just barely outperforms 4/6 coins in the period: https://i.xkqr.org/cfportfolio-vs-6.png. I suspect costs would eat up many of the benefits of rebalancing at this timescale.
This is not too surprising, given the similiarity of coin returns. The mean pairwise correlation is 0.8, the lowest is 0.68. Not particularly good for diversification returns. https://i.xkqr.org/coinscatter.png
> difficulty executing against self-authored plans as state evolves
This is indeed also what I've found trying to make LLMs play text adventures. Even when given a fair bit of help in the prompt, they lose track of the overall goal and find some niche corner to explore very patiently, but ultimately fruitlessly.
A threshold in the single-digit milliseconds range allows the rapid detection of price reversals (signaling the need to exit a position with least loss) in even the most liquid of real futures contracts (not counting rare "flash crash" events).
I don't think LLMs are anywhere close to "mastery" in chess or go. Maybe a nitpick but the point is that a NN created to be good at trading is likely to outperform LLMs at this task the same way way NNs created specifically to be good at board games vastly outperform LLMs at those games.
Seems to me that the outcome would be near random because they are so poorly suited. Which might manifest as
> We also found that the models were highly sensitive to seemingly trivial prompt changes
since they're so general, you need to explore if and how you can use them in your domain. guessing 'they're poorly suited' is just that, guessing. in particular:
> We also found that the models were highly sensitive to seemingly trivial prompt changes
this is as much as obvious for anyone who seriously looked at deploying these, that's why there are some very successful startups in the evals space.
Disagree. Go and chess are games with very limited rules. Succesful trading on the other hand is not so much a arbitary numbers game, but involves analyzing events in the news happening right now. Agentic LLMs that do this and accordingly buy and sell might succeed here.
(Not what they did here, though
"For the first season, they are not given news or access to the leading “narratives” of the market.")
> The models engage in mid-to-low frequency trading (MLFT) trading, where decisions are spaced by minutes to a few hours, not microseconds. In stark contrast to high-frequency trading, MLFT gets us closer to the question we care about: can a model make good choices with a reasonable amount of time and information?
I have a really nice bridge to sell you...
This "failure" is just a grab at trying to look "cool" and "innovative" I'd bet. Anyone with a modicum of understanding of the tooling (or hell experience they've been around for a few years now, enough for people to build a feeling for this), knows that this it's not a task for a pre-trained general LLM.
But I still think the experiment is interesting because it gives us insight into how LLMs approach risk management, and what effects on that we can have with prompting.
also the other curious nature of the markets is its ability to destroy any persistent trading system by reverting to its core stochastic properties and its constant ebb and flow from stability to instability that crescendos into systematic instability that rewrite the rules all over again.
ive tried all sorts of ways to do this and without being a large institution and being able to absorb the noise for neutral or legal quasi insider trading via proximity, for the average joe the emotional/psychological hardness you need to survive and be in the <1% of traders is simply too much, its not unlike any other sports or arts, many dream the dream but only few get interviewed and written about.
rather i think to myself the best trade is the simplest one: buy shares or invest in a business with money or time (strongly recommend against using this unless you have no other means) and sell it at a higher price or maintain a long term DCF from a business you own as leverage/collateral to arbitrage whatever rate your central bank sets on assets in demand or will be in demand.
to me its clear where LLM fits and doesn't but ultimately it cannot, will not, must not replace your own agency.
Edit - additional detail: The original Asirra paper from October 2007 claimed "Barring a major advance in machine vision, we expect computers will have no better than a 1/54,000 chance of solving it" [0]. It took Philippe Golle from Palo Alto a bit under a year to get "a classifier which is 82.7% accurate in telling apart the images of cats and dogs used in Asirra" and "solve a 12-image Asirra challenge automatically with probability 10.3%" [1].
Edit 2: History is chock-full of examples of human ingenuity solving problems for very little external gain. And here we have a problem where the incentive is almost literally a money printing machine. I expect progress to be very rapid.
[0] https://www.microsoft.com/en-us/research/publication/asirra-...
What, so they're better at my hobbies than me? Someone give Claude a 3d printer!
You need domain knowledge to get this to work. Things like "we fed the model the market data" are actually non-obvious. There might be more than one way to pre-process the data, and what the model sees will greatly affect what actions it comes up with. You also have to think about corner cases, eg when AlphaZero was applied to StarCraft, they had to give it some restrictions on the action rate, that kind of thing. Otherwise the model gets stuck in an imaginary money fountain.
But yeah, the AI thing hasn't passed by the quant trading community. A lot of things going on with AI trading teams being hired in various shops.
I'm honestly more hopeful about AI replacing this process than the core algorithmic component, at least directly. (AI could help write the latter. But it's immediately useful for the former.)
If you read the paper you note that they surveyed researchers about the current state of the art ("Based on a survey of machine vision literature and vision ex- perts at Microsoft Research, we believe classification accuracy of better than 60% will be difficult without a significant advance in the state of the art.") and noted what had been achieved as PASCAL 2006 ("The 2006 PASCAL Visual Object Classes Challenge [4] included a competition to identify photos as containing several classes of objects, two of which were Cat and Dog. Although cats and dogs were easily distinguishable from other classes (e.g., “bicycle”), they were frequently confused with each other.)
I was working in an adjacent field at the time. I think the general feeling was that advances in image recognition were certainly possible, but no one knew how to get above the 90% accuracy level reliably. This was in the day of hand coded (and patented!) feature extractors.
OTOH, stock market prediction via learning methods has a long history, and plenty of reasons to think that long term prediction is actually impossible. Unlike vision systems there isn't another thing that we can point to to say that "it must be possible" and in this case we are literally trying to predict the future.
Short term prediction works well in some cases in a statistical sense, but long term isn't something that new technology seems likely to solve.
If other market participants chose not to use something then that would show that it doesn't work.
But I also see this incredible growth curve to LLM's improvement. 2 years ago, I wouldn't expect llm's to one shot a web application or help me debug obscure bugs and 2 years later I've been proven wrong.
I completely believe that trading is going to be saturated with ai traders in the future. And being able to predict and detect ai trading patterns is going to be an important leverage for human traders if they'll still exist
Proves that LLM's are nowhere near close to AGI.
Regarding image classification. As I see it, a company like Microsoft surveying researchers about the state of the art and then making a business call to recommend the use of it as a captcha is significantly more meaningful of a prediction than any single paper from an ML research group. My intent was just to demonstrate that it was widely considered to be a significant open problem, which it clearly was. That in turn led to wider interest in solving it, and it was solved soon after - much faster than expected by people I spoke to around that time.
Regarding stock market prediction, of course I'm not claiming that long term prediction is possible. All I'm saying is that I don't see a reason why quant trading could be used as a captcha - it's as pure a pattern matching task as could be, and if AIs can employ all the context and tooling used by humans, I would expect them to be at least as good as humans within a few years. So my prediction is not the end of quant trading, but rather that much of the work of quants would be overtaken by AIs.
Obviously a big part of trading at the moment is already being done by AIs, so I'm not making a particularly bold claim here. What I'm predicting (and I don't believe that anyone in the field would actually disagree) is that as tech advances, AIs will be given control of longer trading time horizons, moving from the current focus on HFT to day trading and then to longer term investment decisions. I believe that there will still be humans in the loop for many many years, but that these humans would gradually turn their focus to high level investment strategy rather than individual trades.
I've been following these for a while and many of the trades taken by DeepSeek and Qwen were really solid
BTC also performed abysmally during this period with a sustained chop down from $126k to $90k.
That's probably good news for us index fund investors. We need people to believe they're going to beat the market.
The big Quant hedge funds have been using machine learning for decades. I took the coursera RL in finance class years ago.
The idea you are going to beat Two Sigma at their own game with tokens is just an absurdity.
Personally, I think any individual on their own that claims they are doing anything in the algorithmic / ML high frequency space is full of shit.
I could talk like I am too and sound really impressive to someone outside the space. That is much different though than actually making money on what you claim you are doing.
It reminds me of an artist friend when I was younger. She was an artist and I quite liked her paintings. She would tell everyone she is an artist. She was also an encyclopedia when it came to anything art related. She wasn't actually selling much art though. She lived off the $10k a month allowance her rich father gave her. She wasn't even being dishonest but when you didn't know the full picture a person would just assume she was living off her art sales.
That's not what this is. It's a research paper from 3 researchers at MSR.
And if you feeding or harnessing as the blog post puts it in a way that where it reasons things like:
> RSI 7-period: 62.5 (neutral-bullish)
Then it is no better than normal automated trading where the program logic is something along the lines if RSI > 80 then exit. And looking at the reasoning trace that is what the model is doing.
> BTC breaking above consolidation zone with strong momentum. RSI at 62.5 shows room to run, MACD positive at 116.5, price well above EMA20. 4H timeframe showing recovery from oversold (RSI 45.4). Targeting retest of $110k-111k zone. Stop below $106,361 protects against false breakout.
My understanding is that technical trading using EMA/timeframes/RSI/MACD etc is big in crypto community. But to automate it you can simply write python code.
I don't know if this is a good use of LLMs. Seems like an overkill. Better use case might have been to see if it can read sentiments from Twitter or something.
haha, if it would be that easy, most of them would do this? :-D
The thing is - its fucking complicated and most people will give up far before they enter any level of operational capability.
I've developed such a system for myself and Im running it in production (though, not with crypto): And whilte most people will see the complexity in "whatever trading magic you apply", its QUITE the opposite:
- the trading logic itself is simple, its ~ 300 lines
- whats not simple is the part of everything else in the context of "asset management", you need position tracking, state management (orders and positions and account etc.), you need to be able to pour in whatever new quotedata for whatever new assete you identify, the system needs to be stable to work in "mass mode" and be super robust as data provider quality is volatile; you need some type of accounting logic on your side; you need a very capable reporting engine (imagine managing 200 positions simultaneously), I could enlength this list more or less unlimited.
There is MUCH MORE in such an application than the question of "when and how do I trade" - my systems raw source is around 2 MB by today, 3rd party libs and OSS libs not included.
do you want to have a chat by Whatsapp then I can show you quite the opposite! :-) And in my case: Nobody knows, only one friend who is also deep in the stuff; people doing this are usually more quiet, since nobody is interested at all. I have some contacts in academia and shared my ideas with them - none of them said: "this wont work"
(Disclaimer: 25+y IT experience, 15 of them in finance)
But, I havent tested it so far since I do not believe it either :D
Still let me clarify - the trading logic as you say is simple and just 300 lines. That is what LLMs seem to be doing in part in the post. The point I made is that doesn't seem to be a good use case for LLMs given that everything costs token. IMO, you could run this in your complex application without spending that much money on tokens.
If you can explain why original opinion of wasting tokens on something which can "simply" be done in python is wrong, I am all ears.
Well I'm in the space, but I've come across more than one guy who discovered a money making algo, all on their own, with all the right ideas but without the industry standard terms for them.
All logic would suggest this shouldn't be possible, but what I've seen is what I've seen.
[0] https://www.mediawiki.org/wiki/Extension:Asirra
[1] https://web.archive.org/web/20150207180225/https%3A//researc...
- data extraction: It's possible to get pretty good levels of accuracy on unstructured data, eg financial reports with relatively little effort compared to before decent llm's
- sentiment analysis: Why bother with complicated sentiment analysis when you can just feed an article into an LLM for scoring?
- reports: You could use it to generate reports on your financial performance, current positions etc
- code: It can generate some code that might sometimes be useful in the development of a system
And if you're going to tell the model say, 'we want to look for mean reversion opportunities' - then why bother with an LLM?
Another angle: LLM's are trained on the vast swathe of scammy internet content and rubbish in relation to the stock market. 90%+ of active retail traders lose money. If an llm is fed on losing / scammy rubbish, how could it possibly produce a return?
they're not quant-bots that already exist to read in stock prices and make decisions. different kind of ML/AI
from TFA: "We also found that the models were highly sensitive to seemingly trivial prompt changes"
(And I'm fairly sure it would be pretty easy to build a system that uses an LLM and a few other small components to beat Pokemon Red. The experiment you are talking about is deliberately hobbled by using a stock LLM without any such tools to make the whole thing entertaining. But when you are trading, you'd want to give your LLM as much help as possible.)
Rather than just relying on pretraining, you'd use RL on the trade outcomes.
I'll still say that the trading period after October 10th has been brutally choppy. Only now do we have a clear direction (down) where you can at least short with some confidence
LLM indeed can replace average human being.
Individual quant traders aren't competing with Two Sigma. If you're an individual quant trader and you find a signal with $500k/yr capacity, that's awesome. If you're Two Sigma you won't give a single cahoot if it's not a $50M/yr signal. Two completely different ball games. I doubt Two Sigma is even trading on Hyperliquid either.
I use LLMs a lot and I work in finance and I don’t see how a LLM benefits in this space.
Also it looks like none of their data uses any kind of benchmarking. It’s purely a which model did better which I don’t think tells you much.
https://www.reddit.com/r/ClaudePlaysPokemon/comments/1otd4kl...
seems like the big issue is just spending time with the tooling to interact with Pokemon and just that calling an LLM for each button is time consuming.
This kind of error just feels comical to me, and really makes it hard for me to believe that AGI is anywhere near. LLM's struggle to understand the order of datasets, when explicitly told. This is like showing a coin trick to a child, except perhaps even simpler.
No amount of added context or instructions seems to fix these kind of issues in a way that doesn't still feel pretty hobbled. The only way to get the full power out of the model is to conform your problem to the expectations that seem to be baked in - i.e. just change your rendering coordinate system to be z-up.
In addition, I cannot imagine how the selection of securities was chosen. Is XRP seriously part of the proposed asset mix here?
It's hard not to look at this and view it as a marketing stunt. Nothing about the results are surprising and the setup does not seem to make any sense to me to begin with.
I followed the curve for the last month, scalping a few times - I get a feel like panic point is ~180$, hype point ~195$, it's like that most swings. There were earnings yday, people are afraid that the company is over its head already and prefer to de-risk, which I do too sometimes on other stuff. It is true that nvidia is overpriced ofc, but I feel we have maybe a few good runs and that's where the risk, therefore the potential reward, is. I enter around 184, and a bit more around 182. I go to sleep (Im in China), and when I wake up I sell at 194. I got lucky, and I would not do it again before I understand why would nvidia be swinging again.
Is an LLM gonna be any better ? My brain did a classic Bayes analysis, used the recent past as strong signal to my prediction of the future (a completely absurd bias ofc, but all traders are absurd humans), I played a company that wasnt gonna burn me too much, since Im still happy to own shares of nvidia whatever the price, and the money put there was losable entirely without too much pain.
Do I need AI ? Meh. For your next play, do you trust me or chatgpt more ? I can explain my decisions very coherently, with good caveats on my limits and biases, and warnings about what risk to afford when. I experienced losses and gains, and I know the effect and causes of both, and how to deal with them both. I prefer me, to it.
The idea isn't to beat them. It's to pick up the scraps. Same as every small trading operation.
I've seen the books of a guy who makes money hand over fist trading options. He'll be the first one to tell you what he does won't scale.
-Start just as they have here
-Keep improving the prompts in a huge variety of ways to see what improvements can be made
-start getting more and more code generated to complete more and more percentage of the work instead of textual prompting
-start fixing the worst parts with real human knowledge code/tools
-finally show fully working solution that does well, with full analysis of what kind of human intervention was necessary, and even explore what kind of prompting could lead to these human intuition-ed tooling going to whatever incredible lengths necessary to hand-hold the models in the right direction
otherwise... i don't get the points of stopping and saying "doesn't do great"
The reason why RL by backtesting cannot work is that the real market is continuously changing, as all the agents within it, both human and automated, are constantly updating their opinions and strategies.
{kind=link}
{kind=link}