At the core of a latent diffusion model is a de-noising process. It takes a noisy image and predicts what is noise vs what is the real image without noise. You use this to remove a bit of noise from the image and repeat to iteratively denoise an image.
You can use this to generate entirely new images by just starting with complete random noise and denoising til you get a 'proper' image. Obviously this would not give you any control over what you generated. So you incorporate 'guidance' which controls how the denoise works. For stable diffusion this guidance comes from a different neural network called CLIP (https://openai.com/research/clip) which can take some text and produce a numerical representation of it that can be correlated to an image of what the text describes (I won't go into more detail here as it's not really relevant to the VAE).
The problem you have with the denoising process is the larger the image you want to denoise the bigger the model you need, and even at a modest 512x512 (the native resolution of stable diffusion) training the model is far too expensive.
This is where the latent bit comes in. Rather than train your model on a 512x512x3 representation (3 channels R,G,B per pixel) use a compressed representation that is 64x64x4, significantly smaller than the uncompressed image and thus requiring a significantly smaller denoising model. This 64x64x4 representation is known as the 'latent' and it is said to be in a 'latent space'.
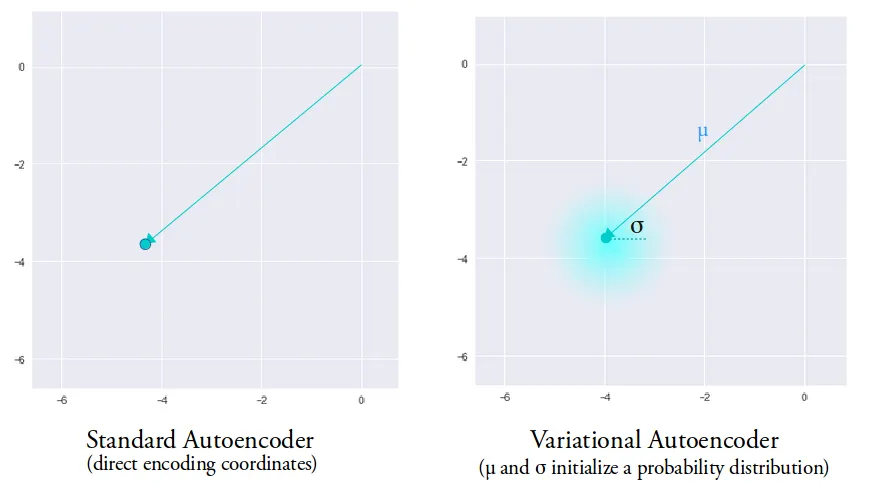
How do we produce the latent representation? A VAE, a variational autoencoder, yet another neural network. You train an encoder and decoder together to encode an image to the 64x64x4 space and decode it back to 512x512x3 with as little loss as possible.
The issue pointed out here is the VAE for stable diffusion has a flaw, it seems to put global information in a particular point of the image (to a crude approximation it might store information like 'green is the dominant colour of this image' in that point). So if you touch that point in the latent you effect the entire image.
This is bad because the denoising network is constructed in such a way that it expects that points close in the latent only effect other points close in the latent. When that's not the case it ends up 'wasting' a bunch of the network on extracting that global data from that point and fanning it out to the rest of the image (as the entire image needs to know it to denoise correctly).
So without this flaw it may be the stable diffusion denoising model could be more effective as it doesn't need to work hard to work around the flaw.
Edit: Pressed enter too early, post is now complete.
It only happens in one specific spot: https://i.imgur.com/8DSJYPP.png and https://i.imgur.com/WJsWG78.png. The fact that a single spot in the latent has such a huge impact on the whole image is not a good thing, because the diffusion model will treat that area as equal to the rest of the latent, without giving it more importance. The loss of the diffusion model is applied at the latent level, not the pixel level, so that you don't have to propagate the gradient of the VAE decoder during the training of the diffusion model, so it's unaware of the importance of that spot in the resulting image.
Some background reading on generic VAE https://towardsdatascience.com/intuitively-understanding-var..., see "Optimizing using pure KL divergence loss".
Perhaps the SD 'VAE' uses a different architecture to a normal vae...
https://twitter.com/Ethan_smith_20/status/175306260429219874...
https://twitter.com/MosaicML/status/1617944401744957443?lang...
This probably got even better and cheaper.
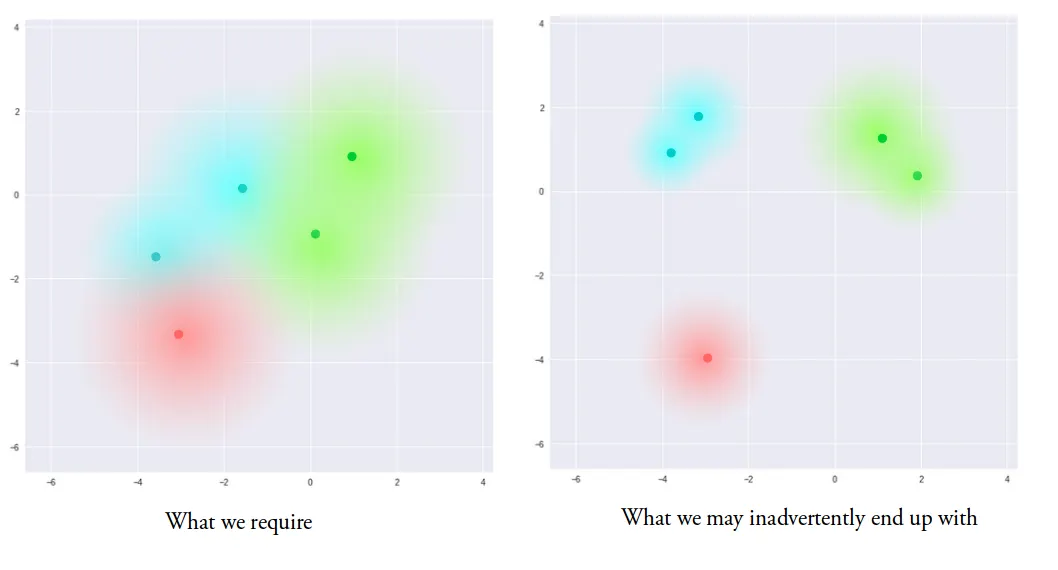
But based on the link you sent, it looks like what we're doing is creating multiple distributions each of which we want patterned on the standard normal. The key diagrams are https://miro.medium.com/v2/resize:fit:1400/format:webp/1*96h... and https://miro.medium.com/v2/resize:fit:1400/format:webp/1*xCj.... You want the little clouds around each dot to be roughly the same shape. Intuitively, it seems like we want to add noise in various places, and we want that noise to be Gaussian noise. So to achieve that we measure the "distance" of each of these distributions from the standard Gaussian using KL divergence.
To me, it seems like one way to look at this is that the KL divergence is essentially a penalty term and it's the reconstruction loss we really want to optimize. The KL penalty term is there to serve essentially as a model of smoothness so that we don't veer too far away from continuity.
This might be similar to how you might try to optimize a model for, say, minimizing the cost of a car, but you want to make sure the car has 4 wheels and a steering wheel. So you might minimize the production cost while adding penalty terms for designs that have 3 or 5 wheels, etc.
But again I really want to emphasize that I don't know this field and I don't know what I'm talking about here. I'm just taking a stab.
https://www.youtube.com/watch?v=vJo7hiMxbQ8 autoencoders
https://www.youtube.com/watch?v=x6T1zMSE4Ts NVAE: A Deep Hierarchical Variational Autoencoder
https://www.youtube.com/watch?v=eyxmSmjmNS0 GAN paper
and then of course you need to check the Stable Diffusion architecture.
oh, also lurking on Reddit to simply see the enormous breadth of ML theory: https://old.reddit.com/r/MachineLearning/search?q=VAE&restri...
and then of course, maybe if someone's nickname has fourier in it, they probably have a sizeable headstart when it comes to math/theory heavy stuff :)
and some hands-on tinkering never hurts! https://towardsdatascience.com/variational-autoencoder-demys...
* multiple sources including OP:
"The SDXL VAE of the same architecture doesn't have this problem,"
"If future models using KL autoencoders do not use the pretrained CompVis checkpoints and use one like SDXL's that is trained properly, they'll be fine."
"SDXL is not subject to this issue because it has its own VAE, which as far as I can tell is trained correctly and does not exhibit the same issues."
- Although the best results for a stand-alone VAE might require increasing the KL loss weight as high as you can to reach an isotropic gaussian latent space without compromising reconstruction quality, beyond a certain point this actually substantially decreases the ability of the diffusion model to properly interpret the latent space and degrades generation quality. The motivation behind constraining the KL loss weight is to ensure the VAE only provides _perceptual_ compression, which VAEs are quite good at, not _semantic_ compression, for which VAEs are a poor generative model compared to diffusion. This is explained in the original latent diffusion paper on which Stable Diffusion was based: https://arxiv.org/pdf/2112.10752.pdf
- You're correct that trading dimensions for channels is a very easy way to increase reconstruction quality of a stand-alone VAE, but it is a very poor choice when the latents are going into a diffusion model. This again makes the latent space harder for the diffusion model to interpret, and again isn't needed if the VAE is strictly operating in the perceptual compression regime as opposed to the semantic compression regime. The underlying reason is channel-wise degrees of freedom have no inherent structure imposed by the underlying convolutional network; in the limit where you hypothetically compress dimensions to a single point with a large number of channels the latent space is completely unstructured and the entropy of the latents is fully maximized; there are no patterns left whatsoever for the diffusion model to work with.
TLDR: Designing VAEs for latent diffusion has a different set of design constraints than designing a VAE as a stand-alone generative model.
{kind=link}
{kind=link}
{kind=link}
{kind=link}